
KI auf Deutsch: Herausforderungen und Innovationen
Wir leben in einer aufregenden Welt, in der Technologie unsere Kommunikation formt und KI-gestützte Sprachmodelle eine immer größere Rolle spielen. Einer Umfrage aus 2023 zufolge, geben 74% der deutschen Unternehmen an, Potenzial in Spracherkennungstechnologien zu sehen, während 70% das generative Potential von KI für Texte, Bilder oder Musik als hoch einschätzen. Auch wir bei 2be setzen aktiv auf KI-Sprachmodelle, denn wir sind davon überzeugt, dass sie unsere Arbeitsprozesse optimieren und innovative Lösungen ermöglichen.
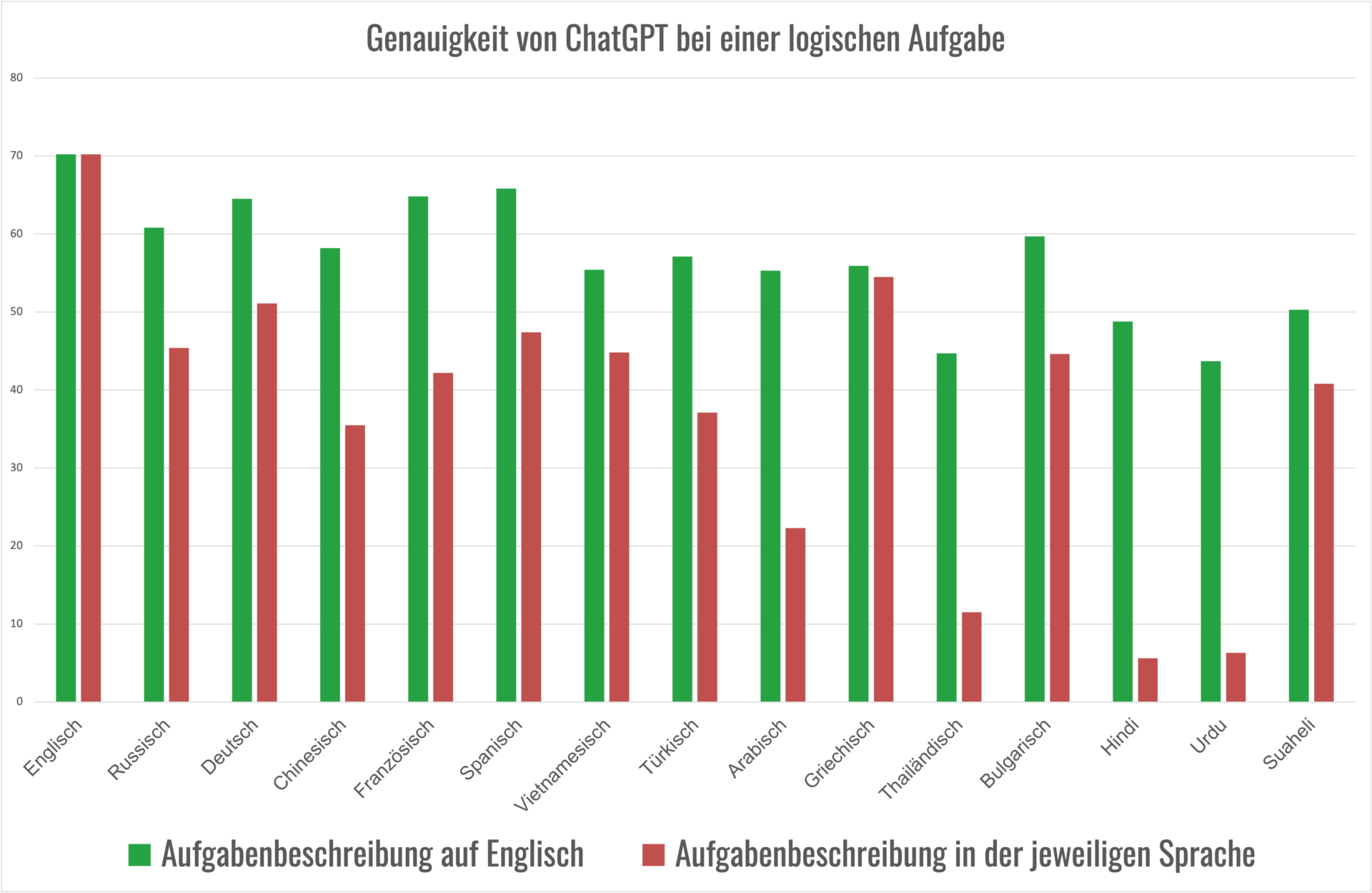
Die Herausforderungen internationaler KI-Modelle für den deutschen Markt
Ob ChatGPT, Claude oder Gemini – Modelle dieser Art weisen zwar Unterschiede auf, haben jedoch eine entscheidende Gemeinsamkeit: Sie stützen sich hauptsächlich auf englischsprachige Daten. Dies wirft eine wichtige Frage auf, insbesondere für uns in Deutschland: Ist dies ein Problem? Unter Umständen kann dies zu Schwierigkeiten führen.
- Bei der Generierung von Texten durch KI-Modelle, die nicht speziell für Deutsch trainiert sind, besteht die Gefahr, dass die Texte eher generisch und durchschnittlich klingen, statt nuanciert und idiomatisch zu sein.
- Ein weiterer Aspekt, der Beachtung finden sollte, ist die unterschiedliche Qualität der Antworten. Die englischen Antworten sind oft detaillierter und präziser, während die deutschen Antworten manchmal vager bleiben oder wichtige Details auslassen.
- Gerade in Fachkontexten oder bei neueren Begriffen stößt die KI häufig an ihre Grenzen. Dies kann dazu führen, dass neu eingeführte Begriffe oder spezifische Fachterminologien nicht korrekt erkannt oder verwendet werden.
Die Qualität eines KI-Modells hängt maßgeblich von den Trainingsdaten ab. Für Sprachen wie Deutsch, die im globalen Vergleich weniger Online-Daten aufweisen, bedeutet dies ein natürliches Handicap.
Lokale Lösungen für globale Technologie?
Doch auch hierfür existieren bereits Lösungsansätze: Forschungsinstitute sammeln mehr diverse und hochwertige deutsche Texte, um KI-Modelle umfassender zu trainieren. Auch die Einbindung von Muttersprachlern wird immer mehr in Betracht gezogen.Es wird ahc an isolierten Modellen gearbeitet, die nicht nur „generisches Deutsch” sprechen, sondern z.B. auch Dialekte verstehen oder sich auf Fachsprachen fokussieren.
Synthetische Daten: Zwischen Effizienz und Herausforderungen
Hier kommen auch synthetische Daten ins Spiel. Sie bieten die Möglichkeit, die Lücken in den Trainingsdaten effektiv zu schließen. Unsere Prognose: Innerhalb der nächsten Monate werden synthetische Datensätze zu einem der wichtigsten Themen der KI-Welt.
Was sind synthetische Daten?
Synthetische Daten sind künstlich erzeugte Informationen, die echte Daten nachahmen. Sie werden eingesetzt, um KI-Modelle zu trainieren, wenn echte Daten nur schwer zu beschaffen sind oder datenschutzrechtliche Bedenken bestehen.
Synthetische Daten sind ein zweischneidiges Schwert: Der Einsatz synthetischer Daten bietet Ihnen eine Reihe von Vorteilen. Ein Vorteil ist der Schutz der Privatsphäre, da keine echten Nutzerdaten verwendet werden. Des Weiteren ermöglichen sie die Simulation eines breiten Spektrums an Szenarien, beispielsweise von seltenen Dialekten bis zu spezifischen Ausdrücken. Darüber hinaus sind sie in großen mengen verfügbar, wodurch sie eine kosteneffektive Lösung darstellen.
Die Erzeugung qualitativ hochwertiger, realistischer Daten ist jedoch technisch anspruchsvoll. Eine unzureichende Qualität der Daten kann zu fehlerhaften oder voreingenommenen KI-Modellen führen, was sich nachteilig auf die Ergebnisse auswirkt. Ein weiteres Risiko ist die Übergeneralisierung, durch die echte sprachliche Nuancen und Komplexitäten übersehen werden könnten.
Bei sorgfältiger Anwendung bergen sie jedoch das Potenzial, die Technologie wesentlich zu verbessern.

Das Masakhane-Projekt und seine globale Bedeutung
Ein Beispiel dafür, wie man Community und neue Datensätze einsetzt, um Sprachmodelle zu verbessern, ist das Masakhane-Projekt. Dieses Vorhaben zielt darauf ab, maschinelle Übersetzungsmodelle speziell für afrikanische Sprachen zu entwickeln. Masakhane konzentriert sich darauf, die Vielfalt und Nuancen lokaler Dialekte und Sprachen wie Yoruba, Swahili oder Amharisch zu erfassen. Dazu arbeitet das Projekt eng mit Gemeinschaften zusammen, um echte und vielfältige Sprachdaten zu sammeln. Diese Beispiele zeigen, dass durch Zusammenarbeit und den Einsatz fortschrittlicher Datenerhebungsmethoden kulturelle Inklusion und technologische Innovation Hand in Hand gehen können.
Bereit für die KI-Zukunft?
Die Entwicklung von KI-Modellen, die umfassend die deutsche Sprache unterstützen, ist ein entscheidender Schritt für die digitale Transformation in Deutschland. Möchten Sie erfahren, wie Ihr Unternehmen von diesen Fortschritten profitieren kann? Kontaktieren Sie uns bei 2be, um mehr über unsere KI-basierten Lösungen zu erfahren.
Neugierig geworden?
Unsere Ansprechpartner helfen Ihnen gerne weiter:

Katharina Zauner
+49 (0)911 / 47 49 49 53
zauner@twobe.de
LinkedIn









